
Metode Pengolahan Data Tekstual Sebagai Fundamental Dari Natural Language Processing

Dalam Digital Transformation metode pengolahan data merupakan pemrosesan bahasa alami atau yang biasa dikenal dengan Natural Language Processing dapat didefinisikan sebagai "penerapan teknik komputasi untuk analisis dan sintesis bahasa dan ucapan alami". Untuk melakukan tugas komputasi ini, pertama-tama kita perlu mengubah bahasa teks menjadi bahasa yang dapat dipahami mesin. Dalam artikel ini, DQLab akan menjelaskan langkah-langkah paling umum yang dapat dilakukan dalam menyiapkan data tekstual sebagai fundamental dari Natural Language Processing. Pada artikel ini akan dibahas beberapa alat yang dapat digunakan untuk melakukan langkah-langkah ini dan juga beberapa contoh kode python untuk menjalankannya.
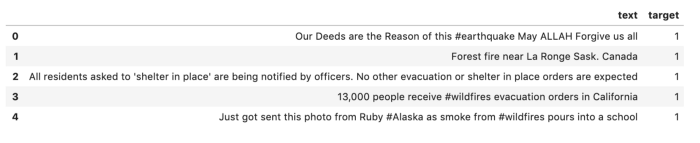
Sepanjang artikel ini, DQLab akan menggunakan data yang diambil dari Kaggle yang dapat diunduh di sini. Dataset ini terdiri atas teks dari tweet dengan variabel target yang mengkategorikannya sebagai tweet tentang bencana yang sebenarnya dan yang tidak. Kode di bawah membaca data ke dalam bingkai data menggunakan pandas. Agar lebih sederhana, pada contoh di artikel ini telah dihapus semua kolom kecuali teks dan variabel target. Berikut adalah kode dan hasil display data nya.
import pandas as pd pd.set_option('display.max_colwidth', -1) train_data = pd.read_csv('train.csv') cols_to_drop = ['id', 'keyword', 'location'] train_data = train_data.drop(cols_to_drop, axis=1) train_data.head()
|
1. Normalization
Salah satu langkah utama dalam memproses data tekstual adalah menghilangkan noise sehingga mesin dapat lebih mudah mendeteksi pola dalam data. Data teks mengandung banyak noise, Noise yang dimaksud disini adalah karakter khusus seperti hashtag, tanda baca, dan angka. Semuanya sulit dimengerti oleh komputer jika mereka ada dalam data. Oleh karena itu, kita perlu memproses data untuk menghapus elemen ini.
Selain itu, penting juga untuk memperhatikan kapitalisasi kata-kata. Jika kita memasukkan versi huruf besar dan huruf kecil dari kata yang sama maka komputer akan melihatnya sebagai entitas yang berbeda, meskipun keduanya mungkin sama. Kode di bawah melakukan langkah-langkah ini. Untuk melacak perubahan yang kita buat pada teks, DQLab telah meletakkan teks bersih ke dalam kolom baru. Outputnya ditampilkan di bawah kode.
import re def clean_text(df, text_field, new_text_field_name): df[new_text_field_name] = df[text_field].str.lower() df[new_text_field_name] = df[new_text_field_name].apply(lambda elem: re.sub(r"(@[A-Za-z0-9]+)|([^0-9A-Za-z t])|(w+://S+)|^rt|http.+?", "", elem)) # remove numbers df[new_text_field_name] = df[new_text_field_name].apply(lambda elem: re.sub(r"d+", "", elem)) return df data_clean = clean_text(train_data, 'text', 'text_clean') data_clean.head()
|

Baca Juga : Mengenal Metode Pengolahan Data Statistik yang Sering Digunakan
2. Stop Words
Stopwords adalah kata-kata yang sering muncul dan untuk beberapa proses komputasi hanya memberikan sedikit informasi atau dalam beberapa kasus justru menimbulkan gangguan sehingga kata-kata tersebut perlu dihilangkan. Hal ini terutama berlaku untuk tugas klasifikasi teks.
Ada kasus lain di mana penghapusan stopwords tidak disarankan atau perlu dipertimbangkan dengan lebih hati-hati. Ini termasuk situasi apa pun di mana makna sepotong teks mungkin hilang dengan penghapusan stopwords. Misalnya, jika kita sedang membangun chatbot dan menghapus kata "tidak" dari frasa "saya tidak senang", maka arti sebaliknya sebenarnya dapat ditafsirkan oleh algoritme. Ini akan sangat penting untuk kasus penggunaan seperti chatbots atau analisis sentimen.
Pustaka python Natural Language Toolkit (NLTK) memiliki metode bawaan untuk menghapus stopwords. Kode di bawah ini menggunakan NLTK untuk menghapus stopwords dari suatu tweet.
import nltk.corpus nltk.download('stopwords') from nltk.corpus import stopwords stop = stopwords.words('english') data_clean['text_clean'] = data_clean['text_clean'].apply(lambda x: ' '.join([word for word in x.split() if word not in (stop)])) data_clean.head()
|

3. Stemming
Stemming adalah proses mereduksi kata-kata menjadi bentuk dasarnya. Misalnya, kata "rain", "raining" dan "rained" memiliki kesamaan, dan dalam banyak kasus memiliki arti yang sama. Proses stemming akan mereduksi ini menjadi bentuk akar "rain". Ini sekali lagi merupakan cara untuk mengurangi noise dan dimensi data.
Library NLTK juga memiliki metode untuk melakukan tugas stemming. Kode di bawah ini menggunakan PorterStemmer untuk membendung kata-kata dalam contoh di atas. Seperti yang dapat dilihat dari output, semua kata sekarang menjadi "rain".
from nltk.stem import PorterStemmer from nltk.tokenize import word_tokenize word_list = ['rains', 'raining', 'rain', 'rained'] ps = PorterStemmer() for w in word_list: print(ps.stem(w)) |
Baca Juga : Teknik Pengolahan Data : Mengenal Missing Values dan Cara-Cara Menanganinya
4. Yuk Dalami Lagi Bersama DQLab!
Ingin mempelajari Python lebih dalam? Ayo mulai belajar bersama DQLab secara GRATIS! Yuk, bergabung di DQLab! Kamu bisa membangun portofolio datamu dengan belajar data science di DQLab. Untuk kamu yang ingin mulai belajar data science atau siap berkarir jadi Data Analyst, Data Scientist, dan Data Engineer, persiapkan diri kamu dengan tepat sekarang. Tidak ada kata terlambat untuk belajar. Yuk #MulaiBelajarData di DQLab.
Dengan belajar di DQLab, kamu bisa:
Menerapkan teknik mengolah data kotor, hasilkan visualisasi data dan model prediksi dengan studi kasus Retail dan Finansial
Dapatkan sesi konsultasi langsung dengan praktisi data lewat data mentoring
Bangun portofolio data langsung dari praktisi data Industri
Akses Forum DQLab untuk berdiskusi.
Simak informasi di bawah ini untuk mengakses gratis module "Introduction to Data Science":
Buat Akun Gratis dengan Signup di DQLab.id/signup
Akses module Introduction to Data Science
Selesaikan modulenya, dapatkan sertifikat & reward menarik dari DQLab
Semangat belajar sahabat Data DQLab!
Penulis : Jihar Gifari
Editor : Annissa Widya
Mulai Karier
sebagai Praktisi
Data Bersama
DQLab
Daftar sekarang dan ambil langkah
pertamamu untuk mengenal
Data Science.